Weights & Biases 
 ¶
¶
LaminDB can be integrated with W&B to track the training process and associate datasets & parameters with models.
# pip install lamindb torchvision lightning wandb
!lamin init --storage ./lamin-mlops
!wandb login
Show code cell output
→ connected lamindb: anonymous/lamin-mlops
wandb: [wandb.login()] Loaded credentials for https://api.wandb.ai from WANDB_API_KEY.
wandb: Currently logged in as: felix_lamin (lamin-mlops-demo) to https://api.wandb.ai. Use `wandb login --relogin` to force relogin
import lightning as pl
import lamindb as ln
from lamindb.integrations import lightning as ll
import wandb
from torch import utils
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from autoencoder import LitAutoEncoder
Show code cell output
→ connected lamindb: anonymous/lamin-mlops
# define model run parameters, features, and labels so that validation passes later on
MODEL_CONFIG = {"hidden_size": 32, "bottleneck_size": 16, "batch_size": 32}
hyperparameter = ln.Feature(name="Autoencoder hyperparameter", is_type=True).save()
hyperparams = ln.Feature.from_dict(MODEL_CONFIG, type=hyperparameter).save()
metrics_to_annotate = ["train_loss", "val_loss", "current_epoch"]
for metric in metrics_to_annotate:
dtype = int if metric == "current_epoch" else float
ln.Feature(name=metric, dtype=dtype).save()
# create all Wandb related features like 'wandb_run_id'
ln.examples.wandb.save_wandb_features()
# create all lightning integration features like 'score'
ll.save_lightning_features()
Show code cell output
! rather than passing a string 'int' to dtype, consider passing a Python object
! rather than passing a string 'int' to dtype, consider passing a Python object
! rather than passing a string 'int' to dtype, consider passing a Python object
! you are trying to create a record with name='mode' but records with similar names exist: 'model_rank', 'is_best_model', 'is_last_model'. Did you mean to load one of them?
# track this notebook/script run so that all checkpoint artifacts are associated with the source code
ln.track(params=MODEL_CONFIG, project=ln.Project(name="Wandb tutorial").save())
Show code cell output
→ created Transform('PTAy1EjZTdD30000', key='wandb.ipynb'), started new Run('gjI1WcguIBB9dpCb') at 2026-07-20 11:42:00 UTC
→ params: hidden_size=32, bottleneck_size=16, batch_size=32
→ notebook imports: autoencoder lamindb-core==2.8.1 lightning==2.6.5 torch==2.13.0 torchvision==0.28.0 wandb==0.28.1
• tip: to identify the notebook across renames, pass the uid: ln.track("PTAy1EjZTdD3", project="Wandb tutorial", params={...})
Define a model¶
We use a basic PyTorch Lightning autoencoder as an example model.
Code of LitAutoEncoder
import torch
import lightning.pytorch as pl
from torch import optim, nn
class LitAutoEncoder(pl.LightningModule):
def __init__(self, hidden_size: int, bottleneck_size: int) -> None:
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, bottleneck_size),
)
self.decoder = nn.Sequential(
nn.Linear(bottleneck_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, 28 * 28),
)
self.save_hyperparameters()
def training_step(
self, batch: tuple[torch.Tensor, torch.Tensor], batch_idx: int
) -> torch.Tensor:
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = nn.functional.mse_loss(x_hat, x)
self.log("train_loss", loss, on_epoch=True)
return loss
def validation_step(
self, batch: tuple[torch.Tensor, torch.Tensor], batch_idx: int
) -> torch.Tensor:
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = nn.functional.mse_loss(x_hat, x)
self.log("val_loss", loss, on_epoch=True)
return loss
def configure_optimizers(self) -> optim.Optimizer:
optimizer = optim.Adam(self.parameters(), lr=1e-3)
return optimizer
Query & download the MNIST dataset¶
We saved the MNIST dataset in a curation notebook which now shows up in the Artifact registry:
ln.Artifact.filter(kind="dataset").to_dataframe()
Let’s get the dataset:
mnist_af = ln.Artifact.get(key="testdata/mnist")
mnist_af
Show code cell output
Artifact(uid='x7BS1VlU96FnNqMf0000', key='testdata/mnist', description='Complete MNIST dataset directory containing training and test data', suffix='', kind='dataset', otype=None, size=54950048, hash='amFx_vXqnUtJr0kmxxWK2Q', n_files=4, n_observations=None, extra_data=None, branch_id=1, created_on_id=1, space_id=1, storage_id=1, run_id=1, schema_id=None, created_by_id=1, created_at=2026-07-20 11:41:43 UTC, is_locked=False, version_tag=None, is_latest=True)
And download it to a local cache:
path = mnist_af.cache()
path
Show code cell output
PosixUPath('/home/runner/work/lamin-mlops/lamin-mlops/docs/lamin-mlops/.lamindb/x7BS1VlU96FnNqMf')
Create a PyTorch-compatible dataset:
mnist_dataset = MNIST(path.as_posix(), transform=ToTensor())
mnist_dataset
Show code cell output
Dataset MNIST
Number of datapoints: 60000
Root location: /home/runner/work/lamin-mlops/lamin-mlops/docs/lamin-mlops/.lamindb/x7BS1VlU96FnNqMf
Split: Train
StandardTransform
Transform: ToTensor()
Monitor training with wandb¶
Train our example model and track the training progress with wandb.
from lightning.pytorch.loggers import WandbLogger
# create the data loader
train_dataset = MNIST(root="./data", train=True, download=True, transform=ToTensor())
val_dataset = MNIST(root="./data", train=False, download=True, transform=ToTensor())
train_loader = utils.data.DataLoader(train_dataset, batch_size=32)
val_loader = utils.data.DataLoader(val_dataset, batch_size=32)
# init model
autoencoder = LitAutoEncoder(
MODEL_CONFIG["hidden_size"], MODEL_CONFIG["bottleneck_size"]
)
# initialize the logger
wandb_logger = WandbLogger(project="lamin")
# add batch size to the wandb config
wandb_logger.experiment.config["batch_size"] = MODEL_CONFIG["batch_size"]
Show code cell output
0%| | 0.00/9.91M [00:00<?, ?B/s]
100%|██████████| 9.91M/9.91M [00:00<00:00, 104MB/s]
0%| | 0.00/28.9k [00:00<?, ?B/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 7.42MB/s]
0%| | 0.00/1.65M [00:00<?, ?B/s]
100%|██████████| 1.65M/1.65M [00:00<00:00, 38.0MB/s]
0%| | 0.00/4.54k [00:00<?, ?B/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 9.88MB/s]
wandb: WARNING The anonymous setting has no effect and will be removed in a future version.
wandb: [wandb.login()] Loaded credentials for https://api.wandb.ai from WANDB_API_KEY.
wandb: Currently logged in as: felix_lamin (lamin-mlops-demo) to https://api.wandb.ai. Use `wandb login --relogin` to force relogin
wandb: setting up run tlbtfq20
wandb: Tracking run with wandb version 0.28.1
wandb: Run data is saved locally in wandb/run-20260720_114202-tlbtfq20
wandb: Run `wandb offline` to turn off syncing.
wandb: Syncing run neat-forest-404
wandb: ⭐️ View project at https://wandb.ai/lamin-mlops-demo/lamin
wandb: 🚀 View run at https://wandb.ai/lamin-mlops-demo/lamin/runs/tlbtfq20
# Create a LaminDB Checkpoint callback and annotate checkpoints with desired metrics
wandb_logger.experiment.id
lamindb_callback = ll.Checkpoint(
dirpath=f"testmodels/wandb/{wandb_logger.experiment.id}",
monitor="val_loss",
mode="min",
save_top_k=3,
features={
"run": {
"wandb_run_id": wandb_logger.experiment.id,
"wandb_run_name": wandb_logger.experiment.name,
},
"artifact": {
**{metric: None for metric in metrics_to_annotate}
}, # auto-populated through callback
},
)
# train model
trainer = pl.Trainer(
limit_train_batches=3,
max_epochs=5,
logger=wandb_logger,
callbacks=[lamindb_callback],
)
trainer.fit(
model=autoencoder, train_dataloaders=train_loader, val_dataloaders=val_loader
)
Show code cell output
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
💡 Tip: For seamless cloud logging and experiment tracking, try installing [litlogger](https://pypi.org/project/litlogger/) to enable LitLogger, which logs metrics and artifacts automatically to the Lightning Experiments platform.
┏━━━┳━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ ┡━━━╇━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━┩ │ 0 │ encoder │ Sequential │ 25.6 K │ train │ 0 │ │ 1 │ decoder │ Sequential │ 26.4 K │ train │ 0 │ └───┴─────────┴────────────┴────────┴───────┴───────┘
Trainable params: 52.1 K Non-trainable params: 0 Total params: 52.1 K Total estimated model params size (MB): 0.208 Modules in train mode: 8 Modules in eval mode: 0 Total FLOPs: 0
/opt/hostedtoolcache/Python/3.13.14/x64/lib/python3.13/site-packages/lightning/pytorch/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
/opt/hostedtoolcache/Python/3.13.14/x64/lib/python3.13/site-packages/lightning/pytorch/trainer/connectors/data_conn ector.py:434: The 'val_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=3` in the `DataLoader` to improve performance.
/opt/hostedtoolcache/Python/3.13.14/x64/lib/python3.13/site-packages/lightning/pytorch/trainer/connectors/data_conn ector.py:434: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=3` in the `DataLoader` to improve performance.
/opt/hostedtoolcache/Python/3.13.14/x64/lib/python3.13/site-packages/lightning/pytorch/loops/fit_loop.py:321: The number of training batches (3) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
! calling anonymously, will miss private instances
`Trainer.fit` stopped: `max_epochs=5` reached.
Since dirpath is explicitly set above, Lamin artifact keys are rooted under that
prefix. When ln.track() is active (the default in this tutorial) and
run_uid_is_version=True, Lamin appends the tracked run UID segment to avoid key
collisions across runs.
wandb_logger.experiment.name
Show code cell output
'neat-forest-404'
wandb.finish()
Show code cell output
wandb: updating run metadata
wandb: uploading history steps 0-9, summary
wandb:
wandb: Run history:
wandb: epoch ▁▁▃▃▅▅▆▆██
wandb: train_loss_epoch █▆▄▃▁
wandb: trainer/global_step ▁▁▃▃▅▅▆▆██
wandb: val_loss █▆▅▃▁
wandb:
wandb: Run summary:
wandb: epoch 4
wandb: train_loss_epoch 0.10938
wandb: trainer/global_step 14
wandb: val_loss 0.11241
wandb:
wandb: 🚀 View run neat-forest-404 at: https://wandb.ai/lamin-mlops-demo/lamin/runs/tlbtfq20
wandb: ⭐️ View project at: https://wandb.ai/lamin-mlops-demo/lamin
wandb: Synced 4 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
wandb: Find logs at: wandb/run-20260720_114202-tlbtfq20/logs
W&B and LaminDB user interfaces together¶
W&B and LaminDB runs:
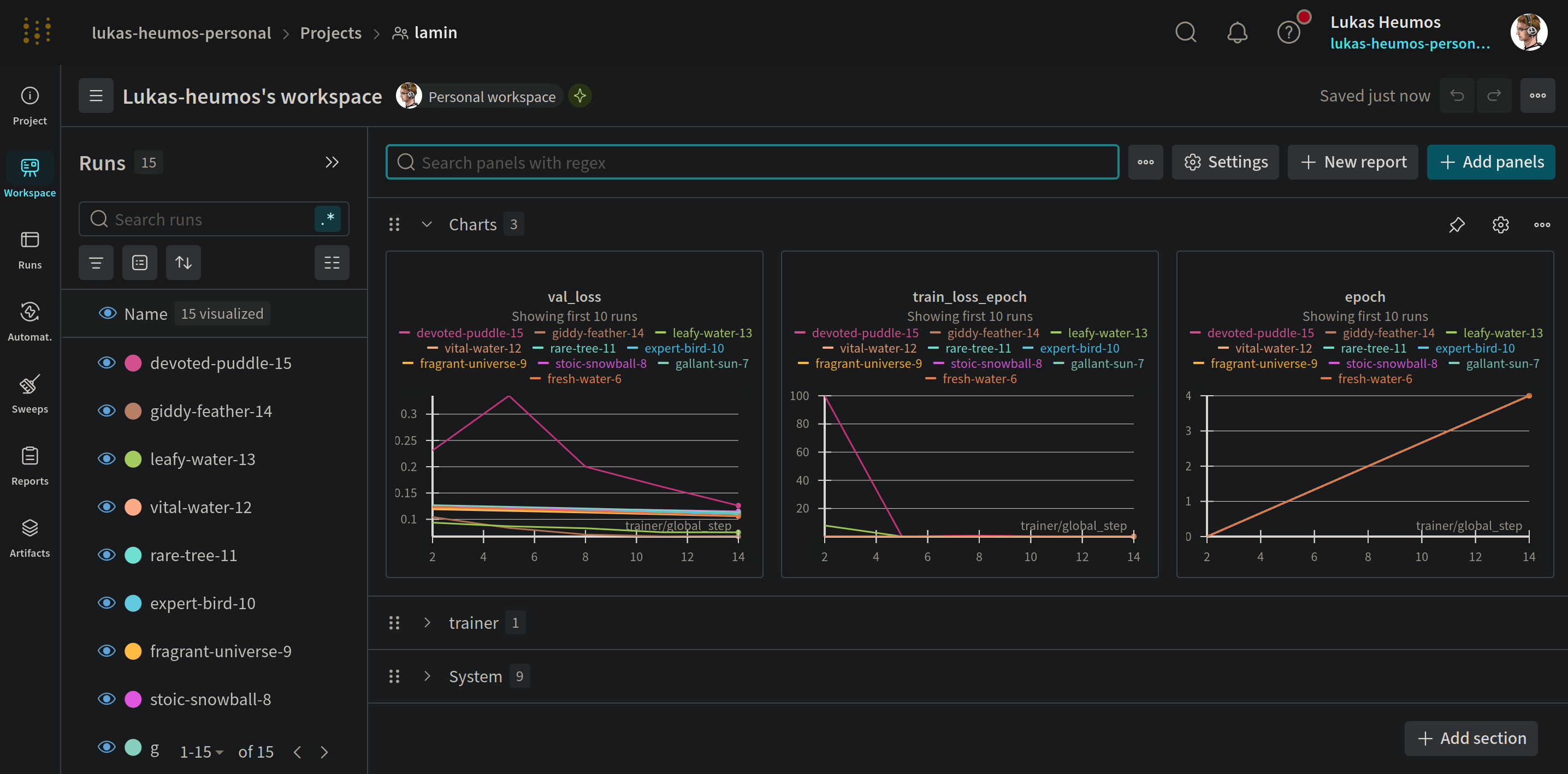
Both W&B and LaminDB capture any runs together with run parameters.
W&B experiment overview |
LaminHub run overview |
|---|---|
|
|
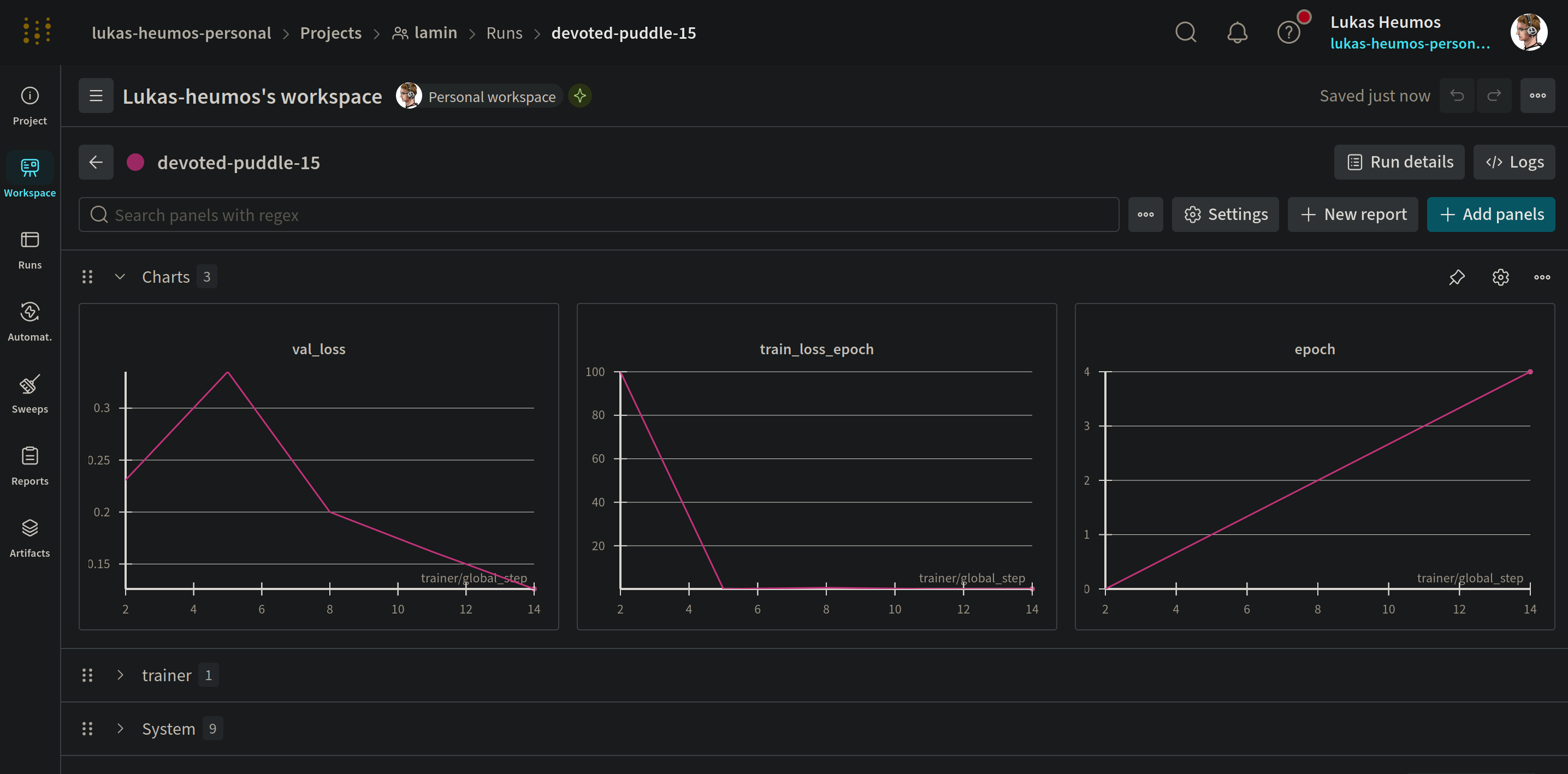
W&B run details and LaminDB artifact details:
W&B and LaminDB complement each other. Whereas W&B is excellent at capturing metrics over time, LaminDB excells at capturing lineage of input & output data and training checkpoints.
W&B run view |
LaminHub run view |
|---|---|
|
|
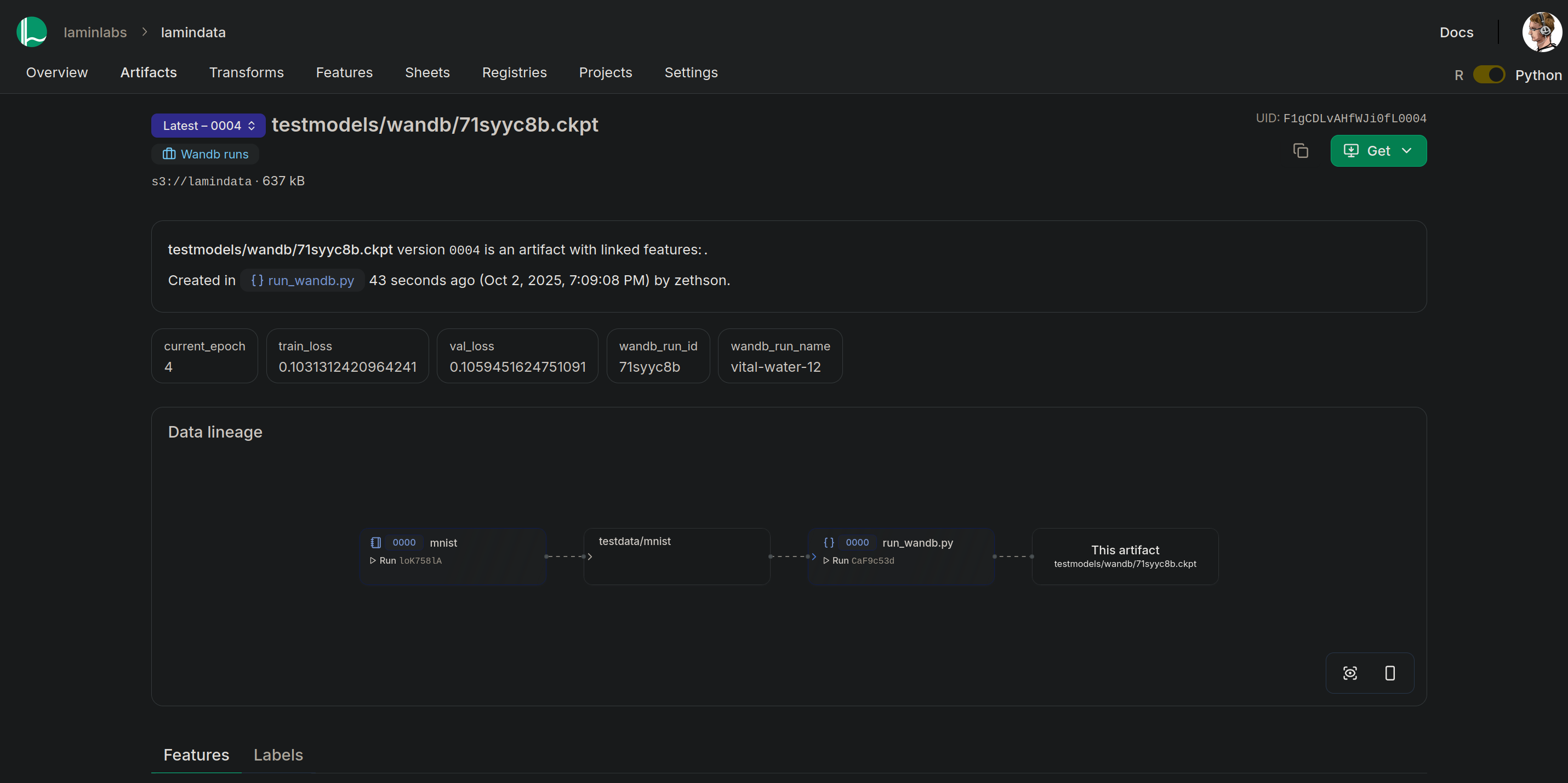
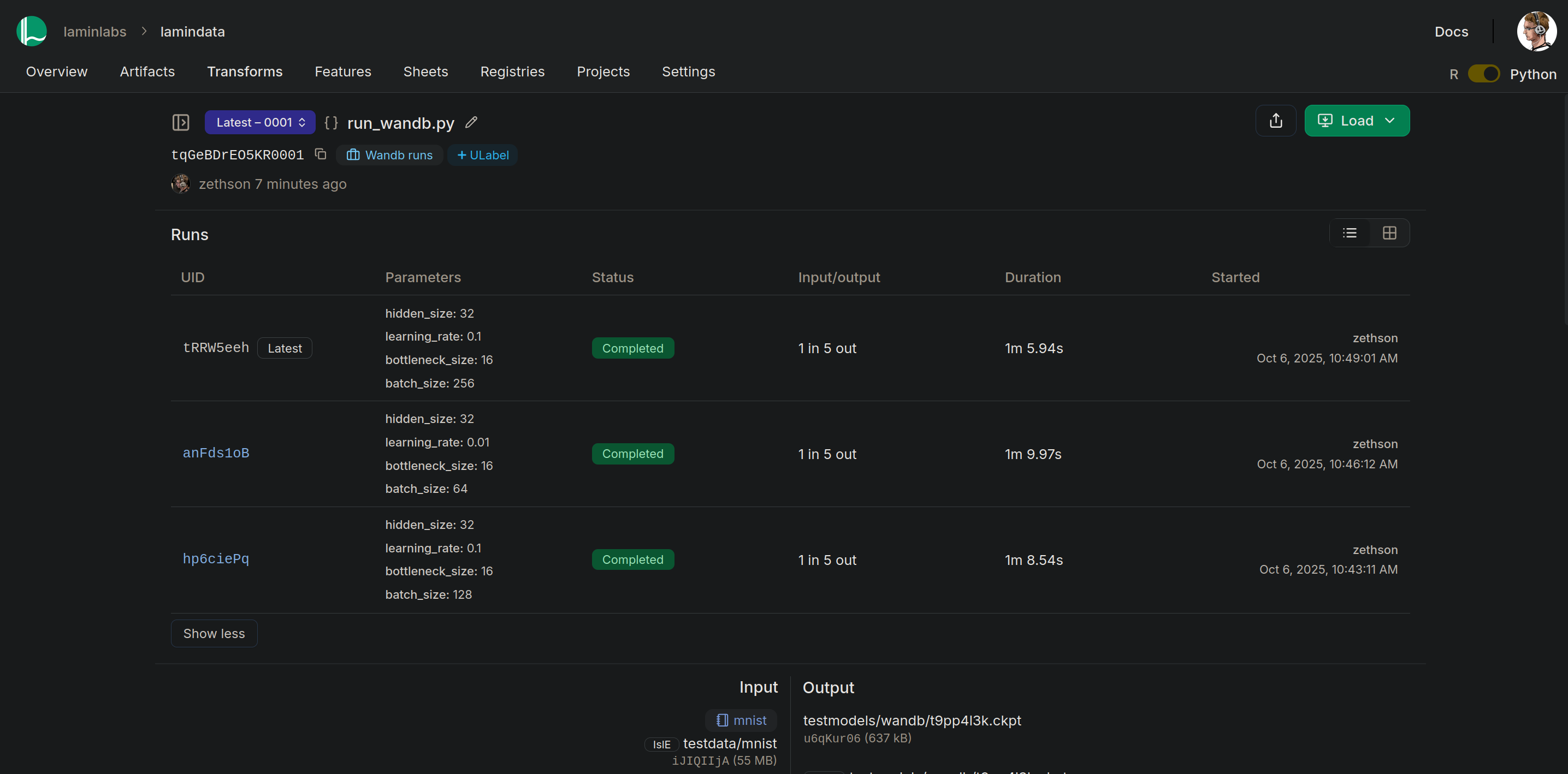
Both frameworks display output artifacts that were generated during the run. LaminDB further captures input artifacts, their origin and the associated source code.
W&B artifact view |
LaminHub artifact view |
|---|---|
|
|
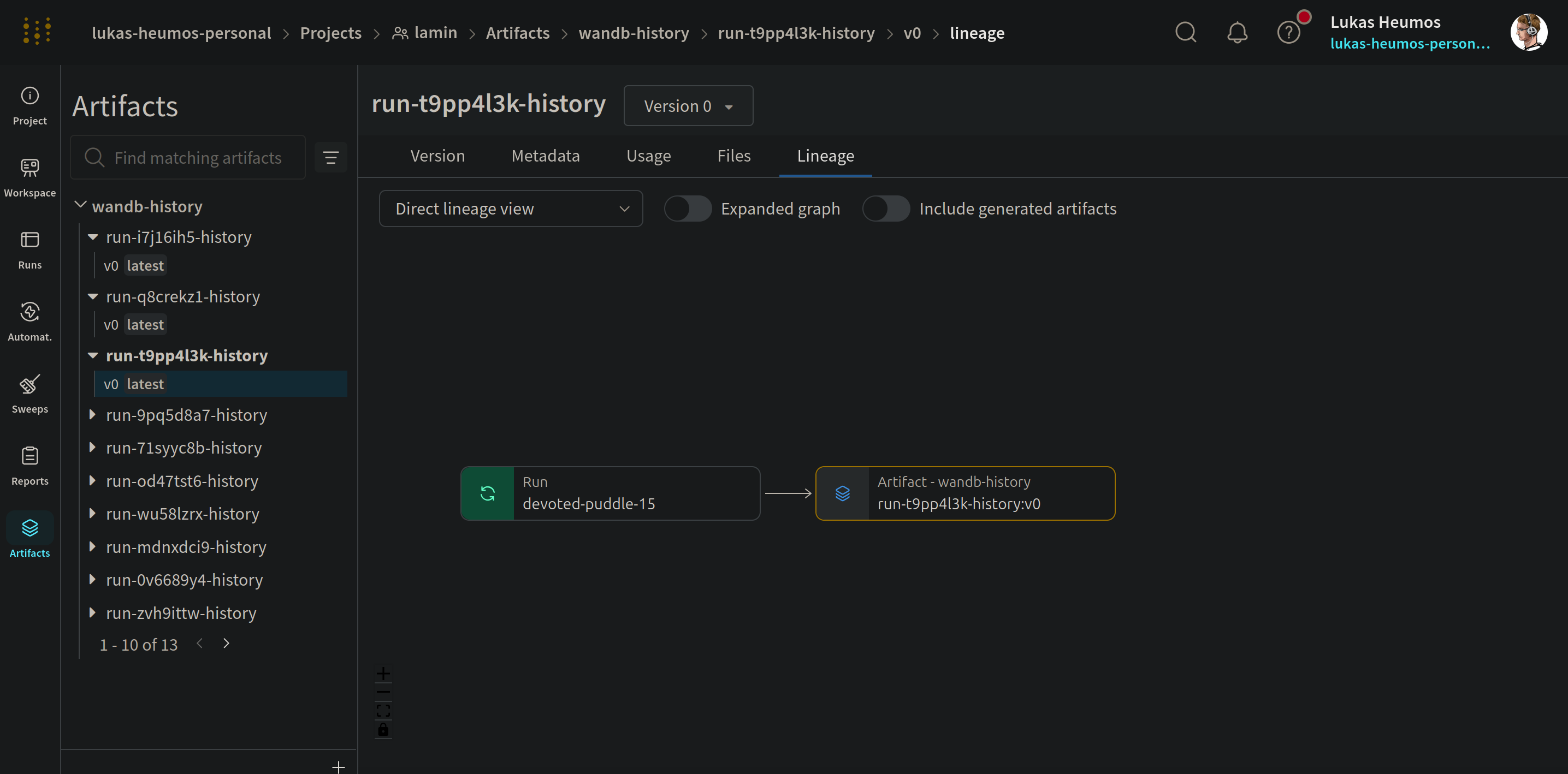
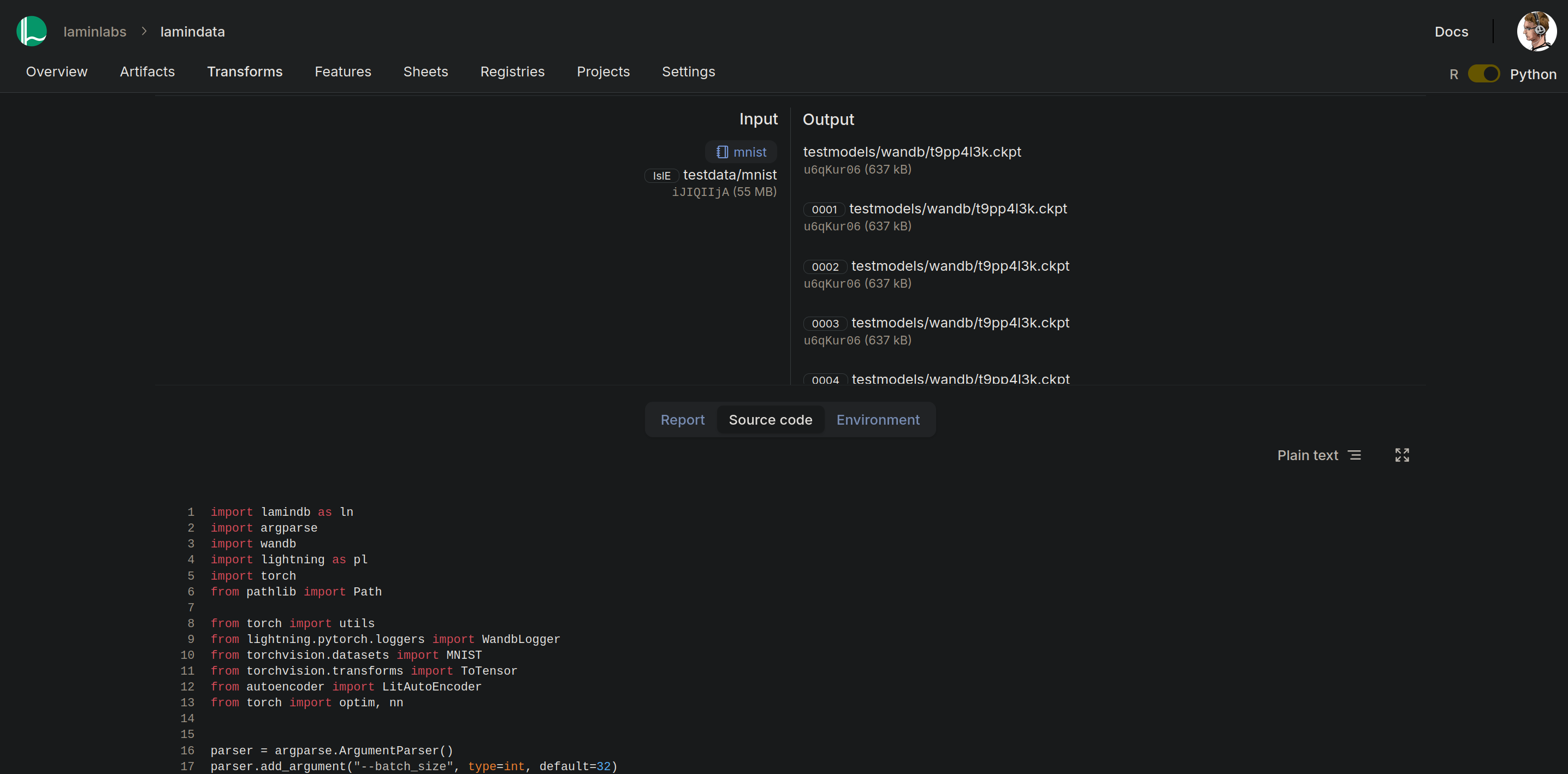
All checkpoints are automatically annotated by the specified training metrics and W&B run ID & name to keep both frameworks in sync:
last_checkpoint_af = (
ln.Artifact.filter(is_best_model=True)
.filter(suffix__endswith="ckpt", is_latest=True)
.last()
)
last_checkpoint_af.describe()
Show code cell output
Artifact: testmodels/wandb/tlbtfq20/gjI1WcguIBB9dpCb/checkpoints/epoch=4-step=15.ckpt (0000) | description: model checkpoint ├── uid: 0vvlCXX0C8xeRIHU0000 run: gjI1Wcg (wandb.ipynb) │ kind: model otype: None │ hash: z8PzXsIBxYO2zRydrPfjzg size: 622.5 KB │ branch: main space: all │ created_at: 2026-07-20 11:42:16 UTC created_by: anonymous ├── storage/path: /home/runner/work/lamin-mlops/lamin-mlops/docs/lamin-mlops/.lamindb/0vvlCXX0C8xeRIHU0000.ckpt ├── Features │ └── current_epoch int 4 │ is_best_model bool True │ is_last_model bool True │ mode str min │ model_rank int 0 │ monitor str val_loss │ save_weights_only bool False │ score float 0.11240699142217636 │ train_loss float 0.10938003659248352 │ val_loss float 0.11240699142217636 └── Labels └── .projects Project Wandb tutorial
To reuse the checkpoint later:
last_checkpoint_af.cache()
Show code cell output
PosixUPath('/home/runner/work/lamin-mlops/lamin-mlops/docs/lamin-mlops/.lamindb/0vvlCXX0C8xeRIHU0000.ckpt')
last_checkpoint_af.view_lineage()
Show code cell output

Features associated with a whole training run are annotated on a run level:
ln.context.run.features
Show code cell output
Run: gjI1Wcg (wandb.ipynb) └── Features └── accumulate_grad_batches int 1 bottleneck_size int 16 hidden_size int 32 logger_name str lamin logger_version str tlbtfq20 max_epochs int 5 max_steps int -1 mode str min monitor str val_loss precision str 32-true wandb_run_id str tlbtfq20 wandb_run_name str neat-forest-404
ln.finish()
Show code cell output
! cells [(10, 12)] were not run consecutively
→ finished Run('gjI1WcguIBB9dpCb') after 19s at 2026-07-20 11:42:20 UTC